Парсер контента

3 декабря 2012
Описание
Очень часто у заказчиков возникает желание брать контентную информацию с ряда сайтов. И конечно же заказчик не собирается это делать ручками, а хочет чтобы все было разово настроено и автоматически работало. Для этого и предназначен модуль shs.parser. Он позволяет по rss каналам брать ссылки на материалы сайтов и парсить контент этих сайтов.
Контент загружается с помощью библиотеки cURL(на стороне сервера) и парсится с помощью библиотеки PHP Simple HTML DOM Parser(включена в модуль). Подробнее про эту библиотеку вы можете почитать на просторах интернета, в данной статье я затрагивать этот вопрос не буду, а лишь опишу функциональные возможности модуля и кратко принцип работы.
Принцип работы модуля прост:
1. Подключается к rss потоку, разбирает xml выдачу.
2. По урлам xml выдачи осуществляет парсинг материалов сайта.
3. Создает новые элементы с распарсенным материалом.
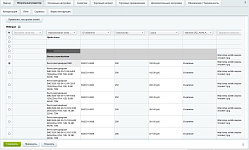
И так. Заходим в модуль Парсер контента в блоке Контент. И мы сразу видим нечто похожее на функционал инфоблоков. На данном этапе мы можем добавить новый парсер. Парсер, терминологией инфоблоков, это некий элемент, обладающий определёнными свойствами и позволяющий парсить контент сайтов.
На данной картинке представлена вкладка Парсера по-умолчанию. Основными параметрами этой вкладки являются.
Название – название файла, обязательное поле, но на работу никак не влияющее.
RSS канал – одно из основных полей, в которое вводится полный адрес rss потока. Именно по этому адресу будет разбираться rss xml. При допущении ошибки в данном поле парсер работать не будет.
ID инфоблока – идентификатор инфоблока, в который будет осуществляться запись вновь созданных элементов.
ID раздела – идентификатор раздела.
Селектор контента – еще один из основных параметров парсера. Это путь контента на сайте, который мы собираемся парсить. Фактически парсер забирает именно содержимое этого селектора.
Кодировка – кодировка сайта, который парсим. В будущем будет добавлено автоопределение.
На данной картинке представлена вторая вкладка парсера - Превью. Тут отображены все параметры, которые связаны с парсингом превью информации. То есть фактически это информация, которая берется непосредственно с rss потока из тега description.
Некоторые параметры кладки:
Удалять теги – удаляет все теги в превью описании.
Кроме следующих – указывается список тегов, которые не требуется удалять. Пример:
- значит, то эти два тега не будут удалены из превью описания.
Первая картинка, как превью – картинка для превью берется как первая из описания.
Заменять пути/сохранять картинки на сервер – интересный параметр, позволяющий подменять пути к картинкам на свои(относительно своего сайта), при этом сохраняя картинки на свой сервер.
Удалять элементы – позволяет удалять обозначенные элементы. Перечисление идет через запятую.
Удалять атрибуты элементов – удаляет атрибуты у заданных элементов, перечисление идет через запятую.
Вкладка детально выглядит идентично вкладке Превью с аналогичными полями и функционалом с той лишь разницей, что контент для Детальной информации берется непосредственно с контента сайта.
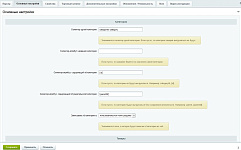
И последняя вкладка - Общие настройки Парсера.
Описание некоторых параметров:
Парсить мета-описание – забирает мета-описание со страницы сайта, котоырй парсим.
Парсить ключевые слова – забирает ключевые слова со страницы сайта.
Запускать по агенту – запуск парсера будет осуществляться по агенту.
Периодичность запуска – периодичность запуска агента.
Контент загружается с помощью библиотеки cURL(на стороне сервера) и парсится с помощью библиотеки PHP Simple HTML DOM Parser(включена в модуль). Подробнее про эту библиотеку вы можете почитать на просторах интернета, в данной статье я затрагивать этот вопрос не буду, а лишь опишу функциональные возможности модуля и кратко принцип работы.
Принцип работы модуля прост:
1. Подключается к rss потоку, разбирает xml выдачу.
2. По урлам xml выдачи осуществляет парсинг материалов сайта.
3. Создает новые элементы с распарсенным материалом.
И так. Заходим в модуль Парсер контента в блоке Контент. И мы сразу видим нечто похожее на функционал инфоблоков. На данном этапе мы можем добавить новый парсер. Парсер, терминологией инфоблоков, это некий элемент, обладающий определёнными свойствами и позволяющий парсить контент сайтов.
На данной картинке представлена вкладка Парсера по-умолчанию. Основными параметрами этой вкладки являются.
Название – название файла, обязательное поле, но на работу никак не влияющее.
RSS канал – одно из основных полей, в которое вводится полный адрес rss потока. Именно по этому адресу будет разбираться rss xml. При допущении ошибки в данном поле парсер работать не будет.
ID инфоблока – идентификатор инфоблока, в который будет осуществляться запись вновь созданных элементов.
ID раздела – идентификатор раздела.
Селектор контента – еще один из основных параметров парсера. Это путь контента на сайте, который мы собираемся парсить. Фактически парсер забирает именно содержимое этого селектора.
Кодировка – кодировка сайта, который парсим. В будущем будет добавлено автоопределение.
На данной картинке представлена вторая вкладка парсера - Превью. Тут отображены все параметры, которые связаны с парсингом превью информации. То есть фактически это информация, которая берется непосредственно с rss потока из тега description.
Некоторые параметры кладки:
Удалять теги – удаляет все теги в превью описании.
Кроме следующих – указывается список тегов, которые не требуется удалять. Пример:
- значит, то эти два тега не будут удалены из превью описания.
Первая картинка, как превью – картинка для превью берется как первая из описания.
Заменять пути/сохранять картинки на сервер – интересный параметр, позволяющий подменять пути к картинкам на свои(относительно своего сайта), при этом сохраняя картинки на свой сервер.
Удалять элементы – позволяет удалять обозначенные элементы. Перечисление идет через запятую.
Удалять атрибуты элементов – удаляет атрибуты у заданных элементов, перечисление идет через запятую.
Вкладка детально выглядит идентично вкладке Превью с аналогичными полями и функционалом с той лишь разницей, что контент для Детальной информации берется непосредственно с контента сайта.
И последняя вкладка - Общие настройки Парсера.
Описание некоторых параметров:
Парсить мета-описание – забирает мета-описание со страницы сайта, котоырй парсим.
Парсить ключевые слова – забирает ключевые слова со страницы сайта.
Запускать по агенту – запуск парсера будет осуществляться по агенту.
Периодичность запуска – периодичность запуска агента.
Вам нужна консультация?
Можете связаться с нами удобным удобным способом
- позвонить по номеру +7-778-003-002-0
- написать на почту sale@ready.kz
- заказать звонок
- заполнить форму обратной связи
Статья полезна для